ClearBuds: Wireless Binaural Earbuds for Learning-based Speech Enhancement
Ishan Chatterjee* Maruchi Kim* Vivek Jayaram*
Shyamnath Gollakota, Ira Kemelmacher-Shlizerman, Shwetak Patel, Steven M. Seitz,
(* Equal contribution)
University of Washington
20th ACM International Conference on Mobile Systems, Applications, and Services (Mobisys 2022)
Demo: Comparison with AirPods
Demo: System Explanation
Demo: Noisy Cafe
Abstract
We present ClearBuds, a state-of-the-art hardware and software system for real-time speech enhancement. Our neural network runs completely on an iphone, allowing you to supress unwanted noises while taking phone calls on the go. ClearBuds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 ms on an accompanying mobile phone.
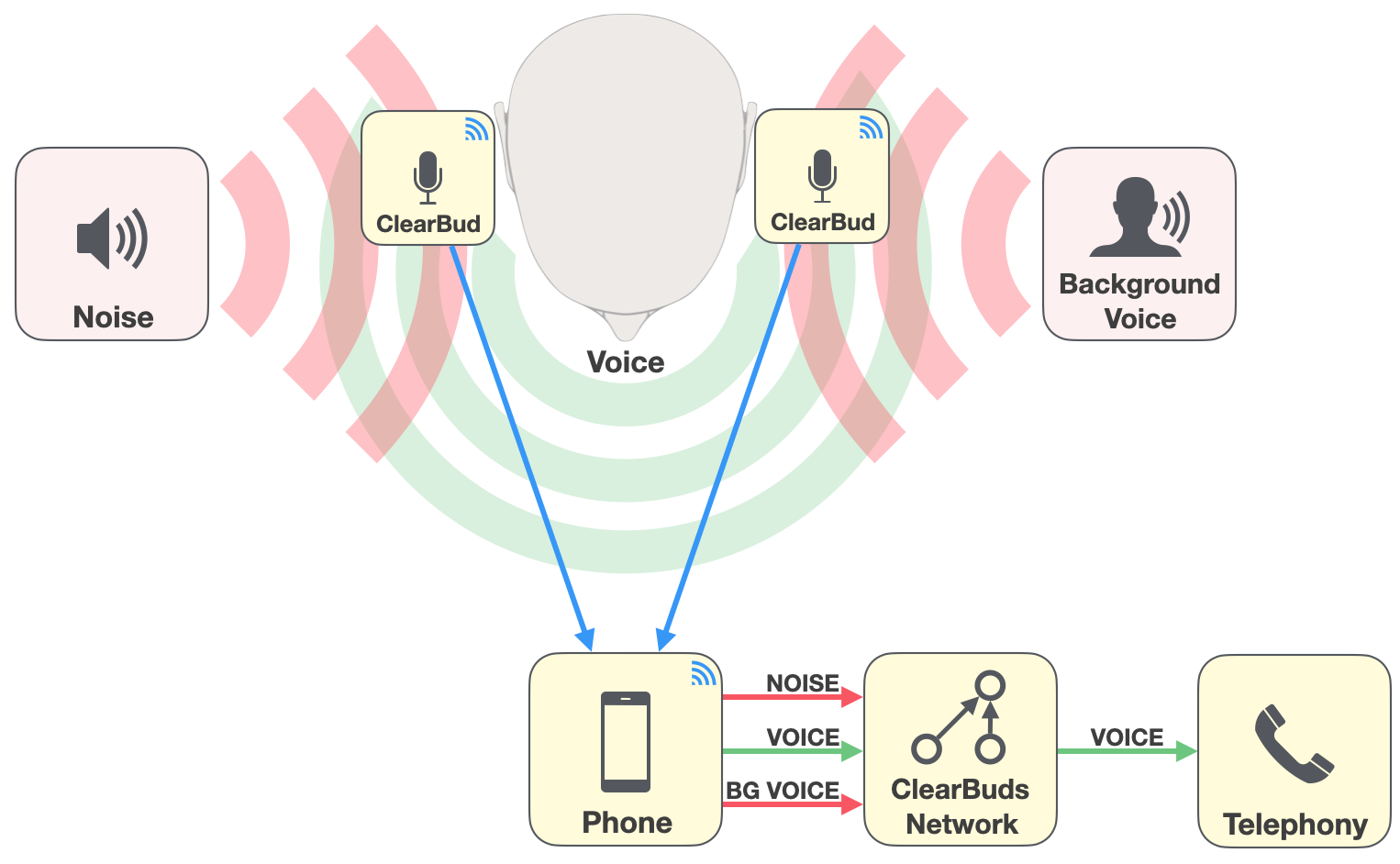
Our goal is to isolate a person's voice in the presence of background noise (e.g. street noise) or other people talking. We perform this separation using a pair of custom synchronized wireless earbuds and a lightweight neural network that runs on an iPhone.
This is a picture of the earbuds. A quarter is provided for a size comparison.
Comparisons
We show comparisons with existing methods on a challenging synthetic audio mixture. Different combinations of background voices and noises are shown
Scenario 1 (Speaker + Other Speaker + BG Noise)
Input Mixture
|
|
|
|
| GT | Ours | Conv Tas-Net [1] |
|---|
|
|
|
|
| Demucs [2] | Perfect Spectrogram Mask (Ratio) | Perfect Spectrogram Mask (Binary) |
|---|
Scenario 2 (Speaker + BG Noise)
Input Mixture
|
|
|
|
| GT | Ours | Conv Tas-Net [1] |
|---|
|
|
|
|
| Demucs [2] | Perfect Spectrogram Mask (Ratio) | Perfect Spectrogram Mask (Binary) |
|---|
Scenario 3 (Speaker + Other Speaker)
Input Mixture
|
|
|
|
| GT | Ours | Conv Tas-Net [1] |
|---|
|
|
|
|
| Demucs [2] | Perfect Spectrogram Mask (Ratio) | Perfect Spectrogram Mask (Binary) |
|---|
Comparison with Krisp.ai
Input Mixture
|
|
|
|
| GT | Ours | Krisp [3] |
|---|
[1] Y. Luo and N. Mesgarani, "Conv-tasnet: Surpassing idealtime–frequency magnitude masking for speech separation". IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2019.
[2] A. Defossez, G. Synnaeve, and Y. Adi, "Real Time Speech Enhancement in the Waveform Domain," Iterspeech, 2020.
[3] www.krisp.ai
Keywords: Binaural speech enhancement, binaural noise suppression, smart earbuds, binaural source separation, airpods speech enhancement
Contact: clearbuds@cs.washington.edu